|
I recently joined Huawei as an AI LLM Researcher. Prior to this, I earned my Ph.D. from Institute of Information Enginering, Chinese Academy of Sciences in July 2024, advised by Prof. Zheng Lin and Prof. Weiping Wang. Previously, I was a research intern at NLC group of Microsoft Research Asia in 2022. And I was a research intern in the Pattern Recognition Center (PRC), WeChat AI at Tencent, supervised by Fandong Meng in 2021. My research interests include visual and language, large language models, and related applications such as visual question answering and LLM's open-source research platform construction. Please reach out to me via email: siqingyi@iie.ac.cn. CV / WeChat / Google Scholar / Github / HuggingFace |

|
{kind=link}
|
|
Google Scholar / Semantic Scholar / DBLP (*: Equal contribution) |
|
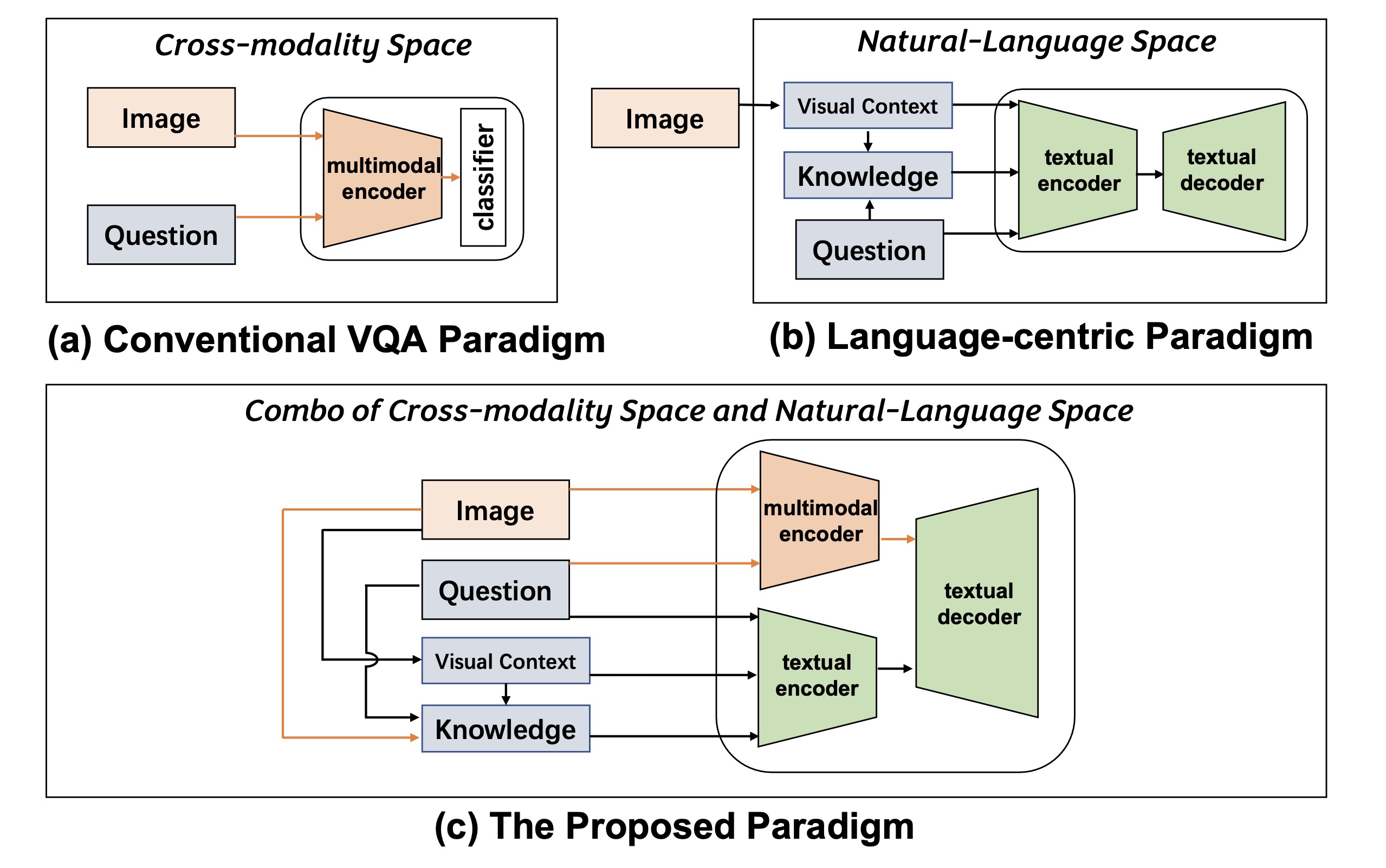
Qingyi Si, Chenyu Mo, Zheng Lin, Huishan Ji, Weiping Wang ACL, 2023 (Main Conference) pdf / code This paper proposes a simple and effective method that mimics human behavior, "thinking while observing", i.e., benefiting from the vast knowledge in natural-language space while making the most of the visual features for better image understanding. Our method establishes a new SoTA accuracy with a 6.17% improvement on OK-VQA. |
|
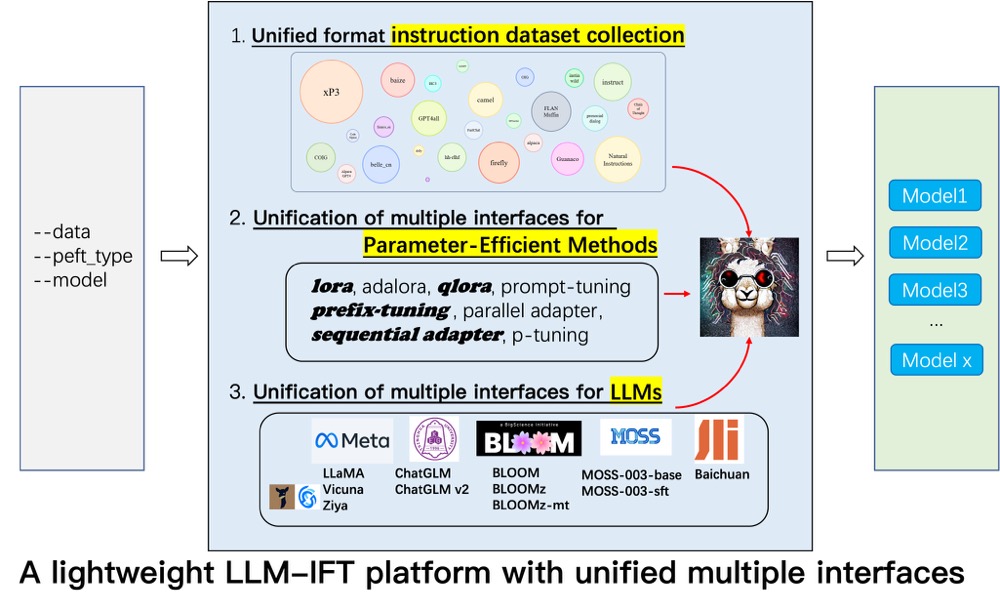
Qingyi Si*, Tong Wang*, Zheng Lin, Xu Zhang, Yanan Cao, Weiping Wang EMNLP, Findings, 2023 (2.2k stars) pdf / code We conduct an thorough empirical study on instruction tuning open LLMs in Chinese. Specifically, we systematically explore the impact of a range of LLM bases, parameter-efficient methods, instruction data types, which are the three most important elements for instruction-tuning. Besides, we also conduct experiment to study the impact of other factors, e.g., chain-of-thought data, language of prompt, and human-value alignment. |
|
Qingyi Si*, Yuanxin Liu*, Zheng Lin, Peng Fu, Weiping Wang EMNLP, 2023 (Main Conference) pdf / code This paper investigates whether a VLP can be compressed and debiased simultaneously by searching sparse and robust subnetworks. To this end, we systematically study the design of a training and compression pipeline to search the subnetworks, as well as the assignment of sparsity to different modality-specific modules. Our results show that there indeed exist sparse and robust subnetworks, which clearly outperform the debiasing SoTAs with fewer parameters |
|
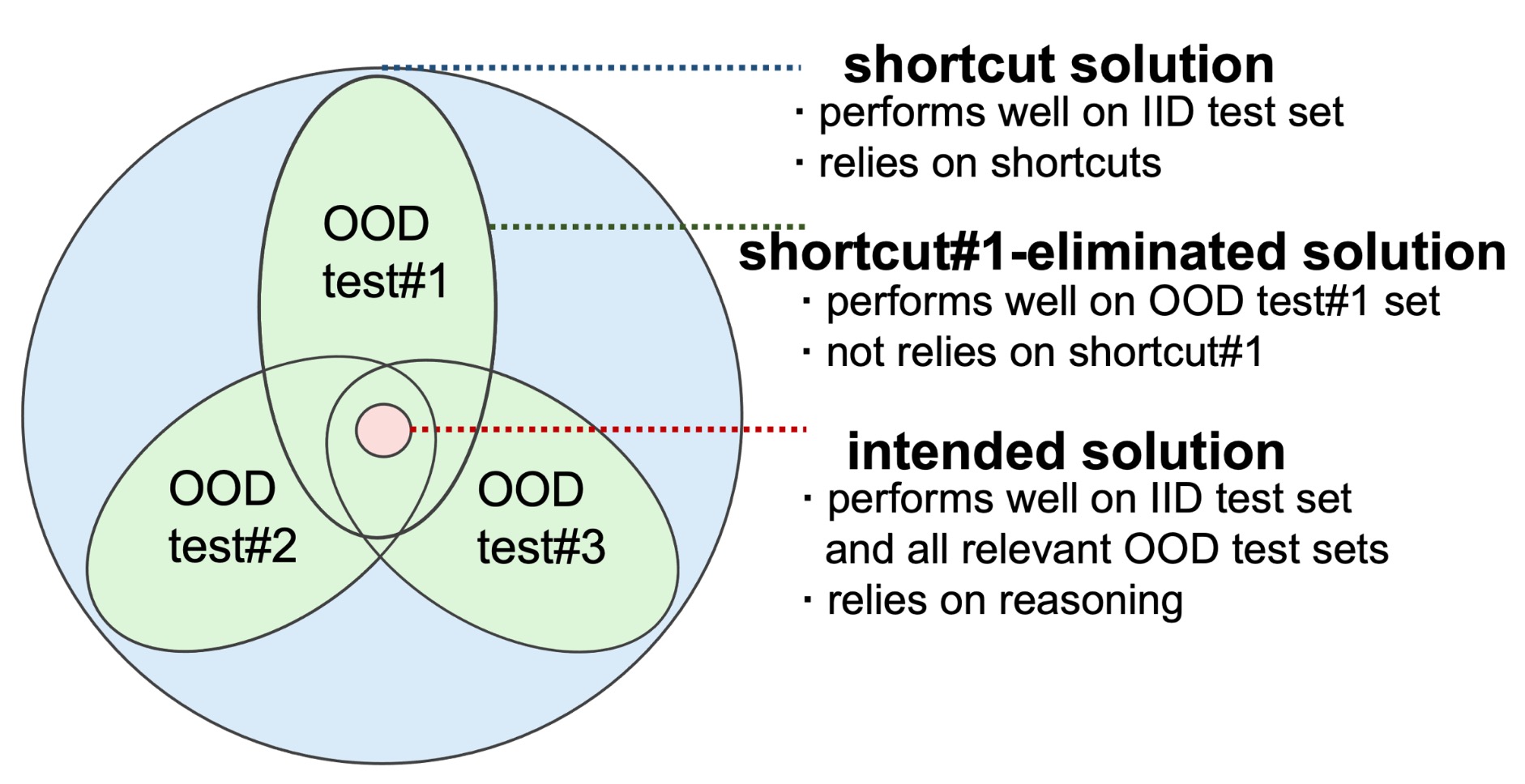
Qingyi Si, Fandong Meng, Mingyu Zheng, Zheng Lin, Yuanxin Liu, Peng Fu, Yanan Cao, Weiping Wang, Jie Zhou EMNLP, Findings, 2022 Received High Praise from Damien Teney pdf / homepage / code / peer review To solve the single-shortcut problem and three issues in the use of current OOD benchmark VQACP v2, we construct and publish a new OOD benchmark VQA-VS including nine OOD test sets corresponding to varying shortcuts. Compared with VQA-CP v2, VQA-VS can provide a more reliable and comprehensive testbed for the reasoning ability of debiasing methods. |

|
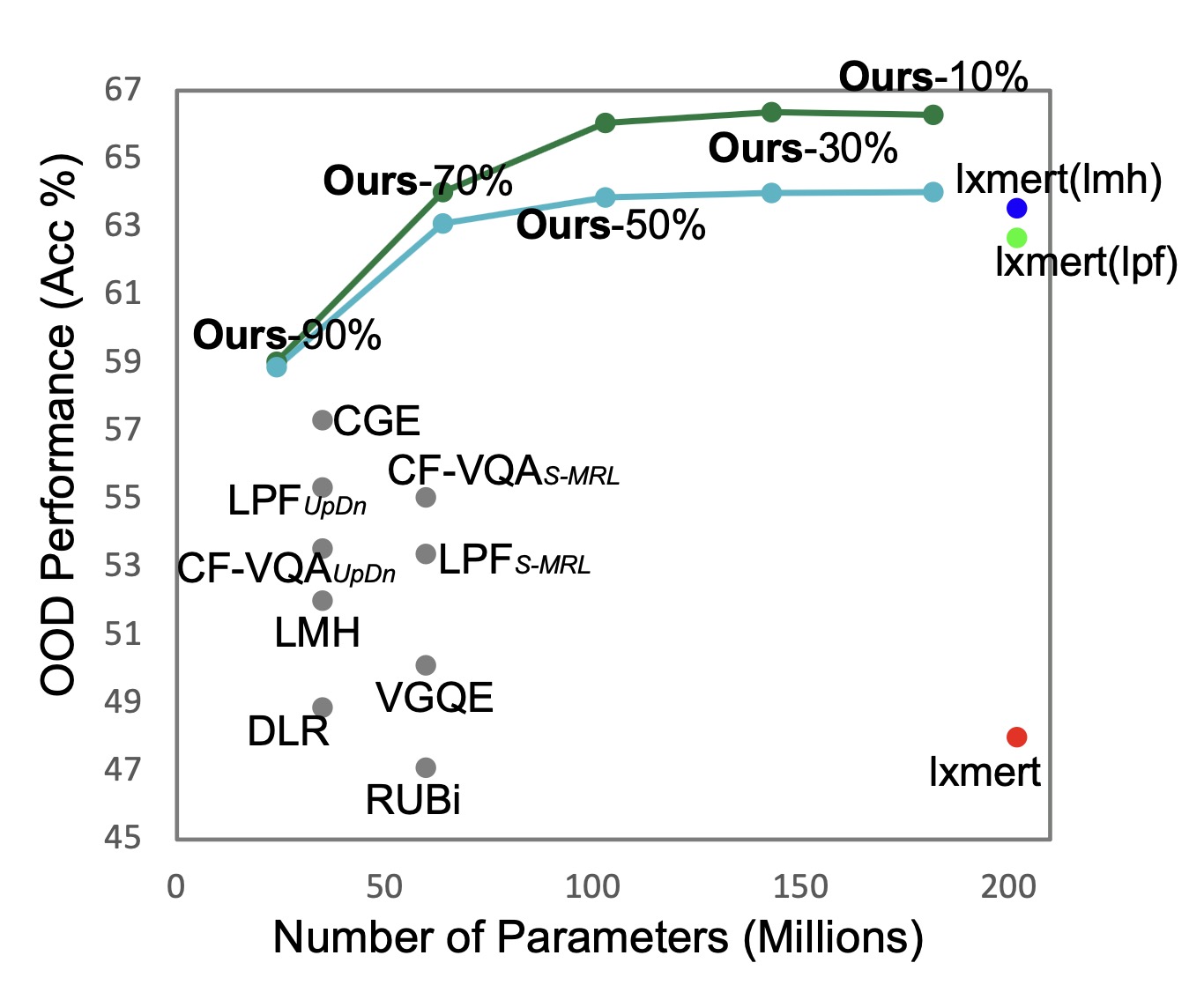
Qingyi Si, Yuanxin Liu, Fandong Meng, Zheng Lin, Peng Fu, Yanan Cao, Weiping Wang, Jie Zhou EMNLP, Findings, 2022 pdf / code We propose a novel method to ameliorate the ID-OOD trade-off problem faced by most existing debaising methods for VQA models. Instead of undermining the importance of the biased samples, our method makes the most of them. . It is compatible with multiple backbone models and debiasing methods, and achieves competitive OOD performance while maintaining ID performance. |
|
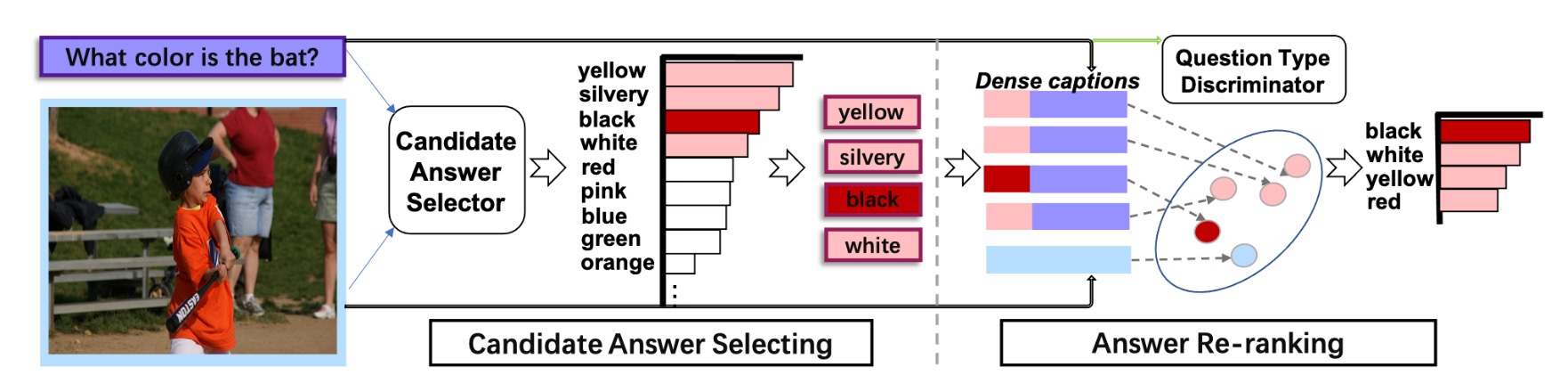
Qingyi Si, Zheng Lin, Ming yu Zheng, Peng Fu, Weiping Wang ACL, 2021 (Main Conference) pdf / code We propose a select-and-rerank (SAR) progressive framework based on Visual Entailment, which can make full use of the interactive information of image, question and candidate answers. In addition, it is a generic framework, which can be easily combined with the existing VQA models and further boost their OOD robustness. Our method establishes SoTA with an improvement of 7.55% on the previous best. |
|
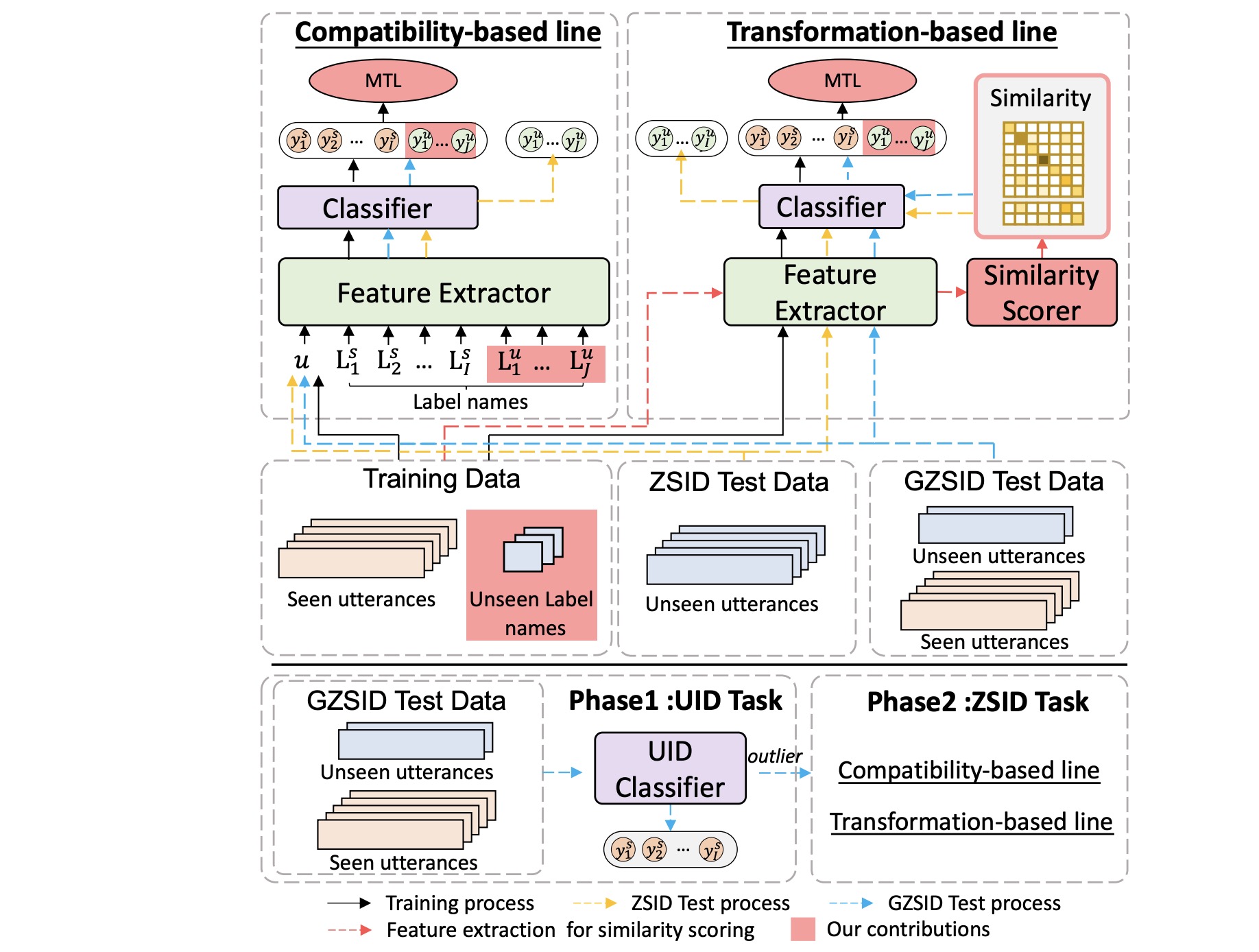
Qingyi Si, Yuanxin Liu, Peng Fu, Zheng Lin, Jiangnan Li, Weiping Wang IJCAI, 2021 (13% Acceptance Rate) pdf / code We propose a class-transductive framework, CTIR, to overcome the limitations of existing zero-shot intent detection models: : 1) They are not good at modeling the relationship between seen and unseen intents. 2) They cannot effectively recognize unseen intents under the generalized intent detection (GZSID) setting. |

|
Duo Zheng, Fandong Meng, Qingyi Si, Hairun Fan, Zipeng Xu, Jie Zhou, Fangxiang Feng, Xiaojie Wang MM, 2022 pdf / code We propose a cooperative object-referring game Dial-the-Diff, where the goal is to locate the different object between two similar images via conversing between questioner and answerer. The task addresses two new challenges in visual dialog, including the difference-oriented dialog strategy and the ability of categorization. |
{kind=link}
|
|

|
project led by Qingyi Si, 2.6k stars We unified the interfaces of instruction-tuning data (e.g., CoT data), multiple LLMs and parameter-efficient methods (e.g., lora, p-tuning) together for easy use. Meanwhile, we created a new branch to build a Tabular LLM. This project can be found here. The data collection can be found here. |
|
|
|
|
|
Design and source code from Jon Barron's website |